The Outbox Model
and the gossip model
and NIP-65
This is a rewrite as of 2024-09-26. Here is the original
I wrote this web page to help people understand what the outbox/gossip model is without me having to explain it over and over again. I'm hoping I can just point people here and not need to keep answering the same follow up questions. I reserve the right to edit and refine this page over time if I change my mind or want to address another subtlety.
Before the Outbox Model

Before the outbox model, people were configuring relays to use. They only posted and pulled notes from the relays that they configured.
The problem quickly became "why can't I find the notes of this person I'm following?" The reason is that the two people had chosen completely disjoint sets of relays.
An even bigger problem was that people were not even aware of the notes that they were not seeing. As they say, nobody is aware of the dog that isn't barking.
The stop-gap solution was to copy notes all over the place. And people configured many dozens of relays to make sure they were heard by everybody. To me this was madness, but it happened and it happened en-masse. This is why I share the meme above. Relays quickly had to become monsterous things with far too much content and they were having trouble handling it all.
If we want to scale to trillions of notes, that model will just not do.
Further, in order to make sure your relay list overlaps with everybody you follow, people were driven to centralize around the same large relays. That centralization weakens nostr's censorship resistance. An attacker only needs to take out about 5 relays and half of nostr would go down (the half that doesn't use the outbox model yet).
Outboxes
The purpose of the model is to make sure you can find the public content of everybody that you follow, and also to make sure that you (and others) can find replies to content that you create. To be clear, this model does not apply to all the 'other stuff' on nostr. It only applies to public content.
The major constraint on the model is that it must be fully distributed. This implies that the model cannot depend on both you and the people you follow using the same relays. If it did, taking out that (or those) relays would be an effective censorship attack.
Luckily such a model, in part, already exists. It is the website model. It is the RSS model. Both of these cases work like this: You post your content to your own website. You find other people's content on their websites. One difference is that nostr has relays, not websites. So you post your content to your outbox relays. You find other peoples content on their outbox relays..
Another difference is that in nostr you can create a digitally signed event that declares which relays you post to. And furthermore, you can declare multiple such relays for redundancy. You do this according to NIP-65. And then you spread it around. Now all a client needs to do is, starting from your public key, seek out your relay list from popular relays it might have been spread to, and then download your events from the relays that you have declared as outboxes.
You can define multiple outboxes. And if one of them censors you, you can remove it from your list, and perhaps add a few more. Clients should periodically load your newest relay list to find out where you are currently posting (in case you get chased around by aggressive censorship).
Inboxes
Posting to the world is just one function in nostr. Another one is sending somebody a message. Generally people @tag other people to send a message to them. Because the person you are tagging might not follow you, you cannot expect them to find the note in your outbox. So for this we have a different solution called an inbox. People choose relays to receive messages on and publish them in their relay list.
So NIP-65 lets you also define inbox relays, for accepting events.
When a client tags somebody, it should send a copy of that event to their inboxes.
NOTE: NIP-65 kind 10002 events use the term "write" for an outbox and "read" for an inbox.
Privacy
The above solves the problem of finding everything while being fully distributed. But in order for your client to find and read my content, I can direct (via my relay list) your client to come over to a relay which you have never even heard of before, which you did not configure, and which you have not vetted. If privacy is a concern to you, then this is a privacy attack vector.
This privacy concern is similar to browser privacy concerns. Asking only for one URL, a website will direct my browser to load lots of other things from other URLs, like grabbing fonts from google and exposing my browsing habits to them.
I recognize this concern. It is real. But there are solutions to this, namely VPNs and Tor.
If someone can come up with a relay model that is fully distributed, and lets you find everything you need to find, and doesn't have this privacy concern, PLEASE SHARE. I was unable to think one up.
So clients can do a few things: They can require users to approve connections to relays (annoying!). And/or they can require clients to approve authentication to relays (which is even more of a privacy concern).
But end users can do something too. They can run a VPN or Tor. And if you actually care about privacy THAT IS WHAT YOU MUST DO.
It is a fool's errand for nostr developers to try to reimplement what Tor or VPNs have given to us. You should just use those.
It is safest to use Tor via a system that was designed by security experts to use Tor, e.g. on qubes or whonix. Torsocks should also be safe since it replaces DNS lookups at the DLL layer, which should get them all.
As a diagram
The following diagram summarizes how a client using the outbox model would interact with relays according to NIP-65: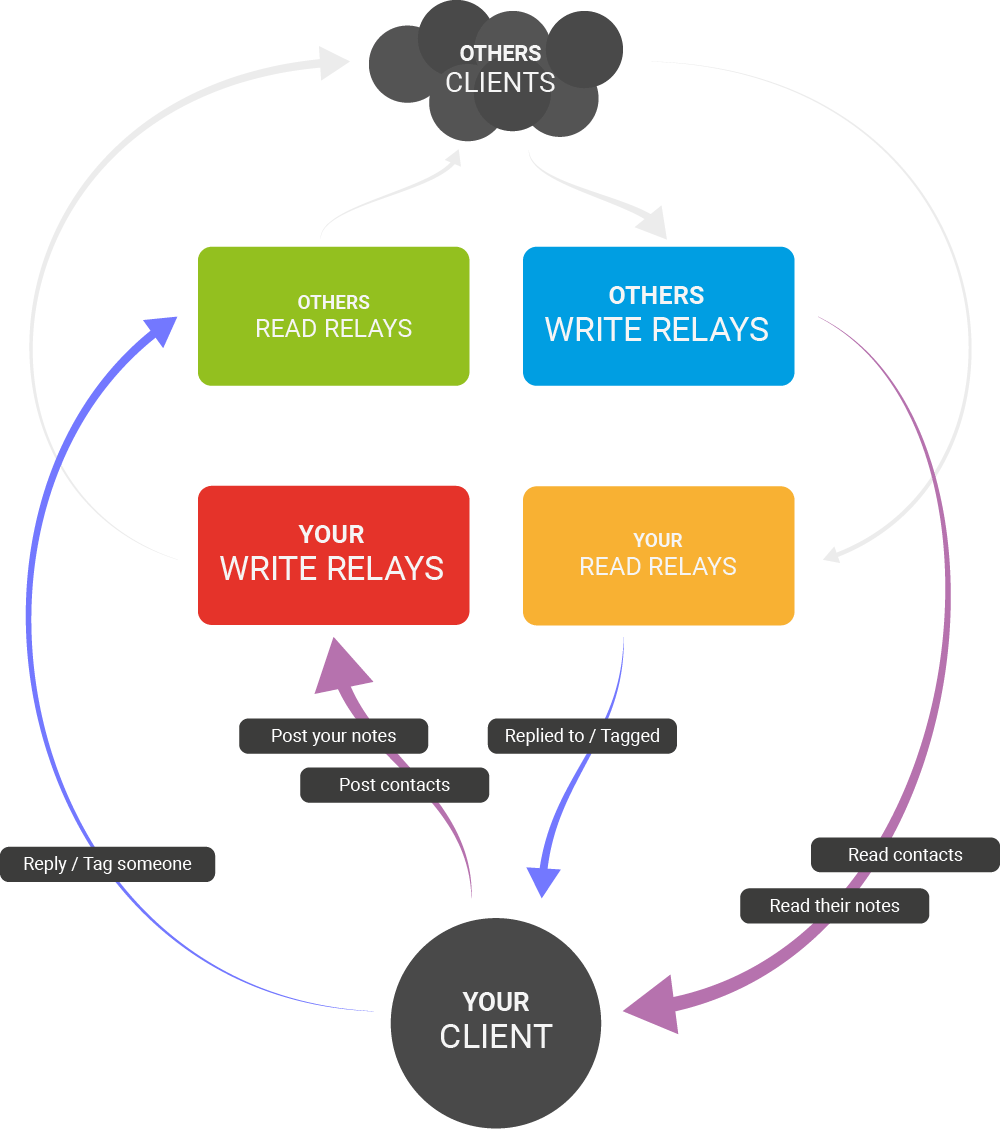
As an animation
Somebody did a great animation.
The Gossip Model
The gossip model is an older term for a more general form of the outbox model. It essentially means "do what the gossip client did before NIP-65 came about".
Before NIP-65, the gossip client dynamically figured out where people were posting (even though they weren't declaring it) and got their posts from those relays.
The gossip client tracks person-relay associations. It uses the following sources:
- Manually entered - These associations are manually entered by the user
- nprofile - These come from nprofile relay data
- NIP-05 - These come from the 'relays' field in the NIP-05 nostr.json file
- kind 3 - These are the 'write' relays that other clients publish into the content of kind-3 Contact List events
- recommended relay URL - These come from event tags that suggest where to get an event authored by the person (so presumably they write to that relay)
- Finally came kind 10002 (NIP-65) - This is relay list metadata, the author professing where they write.
The first 3 come from outside of nostr, two of them are manual entry, and the third is unreliable. So none of those is satisfying for the general solution.
Yes, DNS is unreliable and it has been cancelled. It is a central point of failure. Also, NIP-05 data is not digitally signed. So should we sign it? No. Because nostr.json is a statement made by a DNS domain, not made by a nostr user (although each relays pubkey line arguably is). Furthermore, many nostr users may not want to associate themselves with any DNS domain at all.
The next two (items 4 and 5) come from within nostr. kind 3 is non-standard and many clients don't provide it, so it's not satisfying. Recommended relay URLs are second-hand data, not generated by the author, so it's not a great idea either.
The last one was created to address the shortcomings of the prior five. kind-10002 is an author signed document professing where a person posts (among other things). Unfortunately few clients are creating these (at the time of writing), so these cannot be relied on either. The hope is that will change over time.
So for the time being, the gossip client uses all the methods in that list. And other clients following the gossip model probably should try to do the same.
Personal Relays
This model allows us all to spread out. Once clients sufficiently adopt it, you can run your own relay with rules like this:
- Accept events from me,
- Accept events tagging me,
- Accept kind-10002 events,
- Reject all other events
- Allow me to read anything
- Allow everybody else to read my events
- Allow everybody else to read kind-10002 events
- Block other reading of events
I wrote a general relay called Chorus that operates this way by default, but that allows you to moderate and approve replies so that the public can eventually see those replies (after you approve them).