The Gossip Model
and NIP-65
I wrote this web page to help people understand what the gossip model is without me having to explain it over and over again. I'm hoping I can just point people here and not need to keep answering the same follow up questions. I reserve the right to edit and refine this page over time if I change my mind or want to address another subtlety.
The gossip model enhanced with NIP-65 works great for me. In my view there is nothing much more to do in this regard except that we probably need a DHT sometime down the road. For other client authors who haven't already, I recommend implementing the NIP. I offer suggestions on that at the bottom of this page.
I'm not a salesman. Why should I care of other clients don't use the gossip model? Frankly, I don't. If they like what they are doing, who am I to judge? Sure, I feel bad for their users who cannot see the posts of all the people they follow, and who pull down gigabytes of data trying unsuccessfully to do so. But all those users are free to use the gossip client, so I don't really feel too bad. Will nostr collapse because of relay centralization and congestion? Nostr won't. The central relays might fail under the strain, but all those that use the gossip model will be largely unaffected.

The gossip model is what makes the most sense to me, to fiatjaf, and others (I mention fiatjaf, but to be clear this is my webpage that he had no input into)
Note: This model doesn't work for every usage pattern in nostr, but is intended for the purpose of following people; I recently recommended against this model for developing github on nostr.
Reading someone's posts from where they wrote them
The simplest characterization of the gossip model is just this: reading the posts of people you follow from the relays that they wrote them to.
There are a number of implications to that:
- You need to find out where they wrote them
- You need to dynamically connect there, even if the client's user didn't configure such relays
The Most Common Alternative
The most common alternative is for users to configure read and write relays, and to read events from their configured read relays.
The somewhat obvious problem with this setup is that you might follow somebody who doesn't write to the relays you read from. And if nobody copies their events onto the relays you read from, then the events are simply not found.
It is important to recognize that there is no indication of this. You will just see fewer events. Nobody notices the events that are not there. I think this would be a bigger issue if they did. When people try a client that uses the gossip model, they discover the notes they were missing.
Besides not seeing notes from all the people you want to follow, there are other problems with this approach:
- Because people want to be heard by clients that use this older approach, they will post to the most commonly used relays (I am myself compelled to do this). This centralizes nostr, and it overloads those relays.
- Because people aren't sure which relays you might be listening on, they post to a huge number of relays in order to have the widest reach. In aggregate, this overloads the nostr relays.
- Because they are missing events, they will configure many read relays, often causing the same events to be downloaded many times over. Not only does this load the nostr network, it sometimes uses up their data allowance.
Finding out where they post
This is the hardest part at the moment. There is no sure-fire way to find out where somebody's post are going to be.
The gossip client tracks person-relay associations. It uses the following sources:
- Manually entered - These associations are manually entered by the user
- nprofile - These come from nprofile relay data
- NIP-05 - These come from the 'relays' field in the NIP-05 nostr.json file
- kind 3 - These are the 'write' relays that other clients publish into the content of kind-3 Contact List events
- recommended relay URL - These come from event tags that suggest where to get an event authored by the person (so presumably they write to that relay)
- kind 10002 (NIP-65) - This is relay list metadata, the author professing where they write.
The first 3 come from outside of nostr, two of them are manual entry, and the third is unreliable. So none of those is satisfying for the general solution.
Yes, DNS is unreliable and it has been cancelled. It is a central point of failure. Also, NIP-05 data is not digitally signed. So should we sign it? No. Because nostr.json is a statement made by a DNS domain, not made by a nostr user (although each relays pubkey line arguably is). Furthermore, many nostr users may not want to associate themselves with any DNS domain at all.
The next two (items 4 and 5) come from within nostr. kind 3 is non-standard and many clients don't provide it, so it's not satisfying. Recommended relay URLs are second-hand data, not generated by the author, so it's not a great idea either.
The last one was created to address the shortcomings of the prior five. kind-10002 is an author signed document professing where a person posts (among other things). Unfortunately few clients are creating these (at the time of writing), so these cannot be relied on either. The hope is that will change over time.
So for the time being, the gossip client uses all the methods in that list. And other clients following the gossip model probably should try to do the same.
Bootstrapping
There is manual bootstrapping: manually entered associations, nprofile data pasted in, and NIP-05 nostr.json relay lookups. The last one is rather convenient too (follow me at "mike@mikedilger.com") but requires the person to associate themselves with a DNS domain. But we should have automatic bootstrapping for a better user experience.
So NIP-65 introduced a new way to find where someone posts. That is the kind-10002 relay list. But how can you get ahold of such a list? If people only post these lists where they normally post, how can you find out where they normally post, to get the list, to find out where they normally post? It's a chicken-and-egg problem.
NIP-65 suggests that these relay lists should be posted all over the place, sprayed far and wide. So you can ask any popular relay and it will probably know. That's the goal anyway.
In order to facilitate the ability to write these events to many relays, many of which want payment, NIP-65 designed the kind-10002 event such that it was small, separate from other metadata, is replaceable, and has no content that needs to be moderated. And it suggests that relays accept this event without payment as a special case.
I think this solution is sufficient currently, given that some people are trying to store all their events on all the relays. But eventually with millions of nostr users it won't scale.
DHT
So I think the eventual solution will be a DHT. DHTs allow the data to be made available in a distributed fashion, and not every node needs to know every record, so they can spread out the data. Each piece of data is held redundantly, but not so redundant that every node has it. I don't know enough about DHTs to know if this can be made censorship resistant, but that would be top priority.
Outboxes and Inboxes
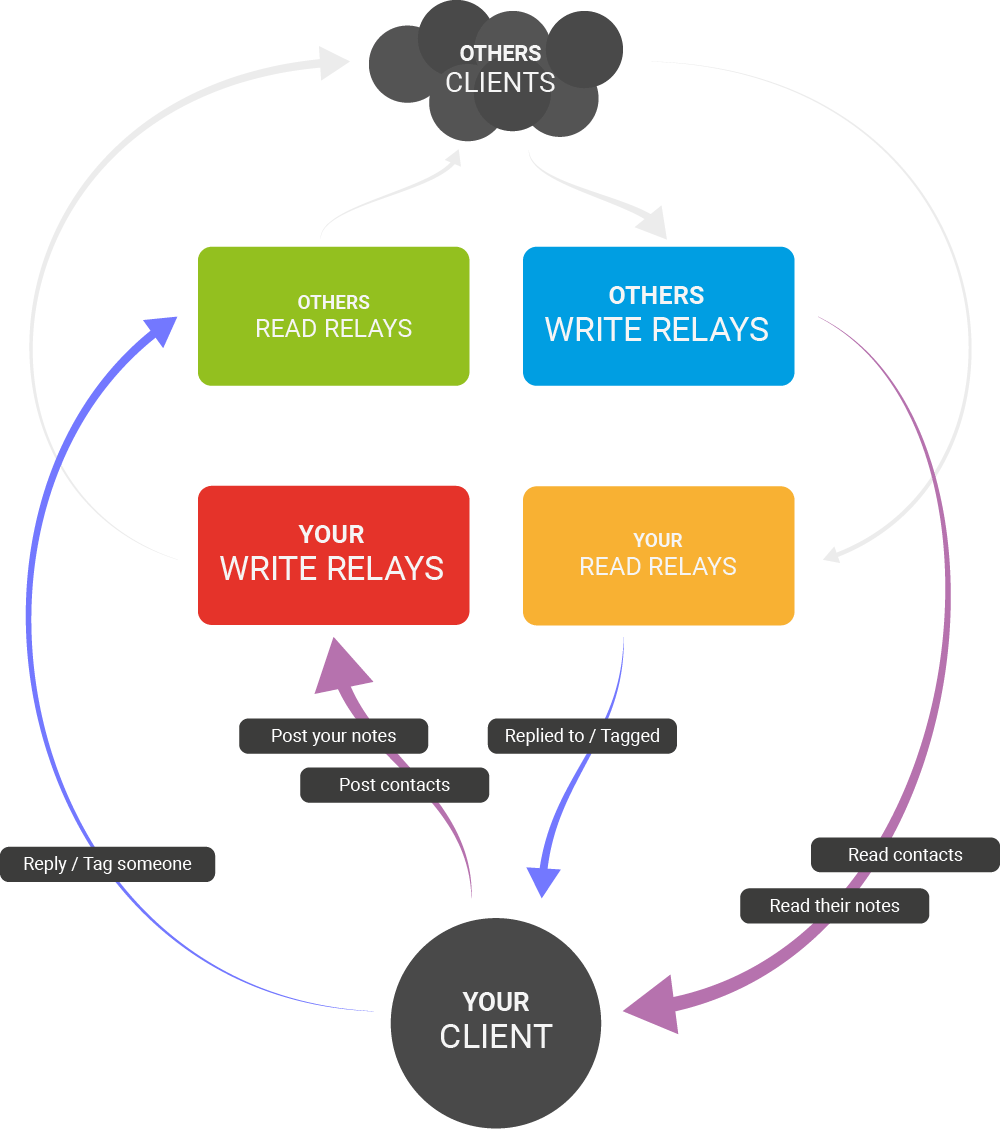
Write relays are kind of like outboxes. They are the posts you are sending out to the world, to be seen on other people's feeds.
NIP-65 also defines read relays. These are like an inbox, where you pick up events that are addressed to you, that tag you. NIP-65 compliant clients will write events that tag you into at least some of your read relays. This way to you can find them even if you don't follow the person who created the event.
The following diagram summarizes how a client using the gossip model would interact with relays according to NIP-65:
Personal Relays
This model allows us all to spread out. Once clients sufficiently adopt it, you can run your own relay with rules like this:
- Accept events from me,
- Accept events tagging me,
- Accept kind-10002 events,
- Reject all other events
- Allow me to read anything
- Allow everybody else to read my events
- Allow everybody else to read kind-10002 events
- Block other reading of events
UPDATE: I have released the chorus relay chorus relay.
UPDATE: I have realized that moderation is still needed. Clients read other people's inboxes to find replies. :-/
The Resistance
There is some resistance to the gossip model.
"I want to control which relays my client connects to"
This is fair. If you decide to follow Steve Bellovin, do you want to manually approve reading from his relays? That's fine. Clients can interject that step into the process and still be using the gossip model. The gossip client presumes that if you want to follow Steve Bellovin, you have given it the authority to figure out where he posts and get his stuff.
Browsers have the same issue. If you go to a web page, that web page instructs your browser to go get many resources from other websites. Unless you install uBlock Origin or similar technology, it just does it automatically. I personally do have uBlock Origin installed and I personally approve or reject each such fetch for each website I visit, so I totally understand the desire for this control. But nostr is only fetching notes, notes which don't run JavaScript, so I'm less concerned. Could some relay be tracking you? Maybe.
In any case, this is solvable without abandoning the gossip model.
"I would have to start over from scratch"
Some client authors believe the work required to change is enormous. I think this comes mostly from a lack of visibility into what is required:
- You need a database table mapping person-relay
- You need columns in that table representing all the ways the assocation could have been made (see the list above) perhaps as timestamps of the last time it was made
- You need to update that table whenever you process data representing one of those columns.
- You need a function that uses that table to generate a ranked-relay list for a given person
- Then you need to assign pubkeys to relays and connect to relays in such a way as to be redundant-enough and to cover all the pubkeys, using the Gossip Relay Picker library or similar logic.
But maybe some clients do need major overhauls. Is it worth it? It depends on what the client is setting out to do. I believe clients that support the gossip model will be the clients that most users want to use, and so they will win in the competition of ideas.
Client Support
Here are some nostr clients that implement the gossip-model (with or without NIP-65 support). This list is not complete and I can't keep it up to date as many clients are now implementing it.
- gossip
- coracle and coracle social
- Nozzle
- camelus.app
- snort
- Lume
- Iris
- NDK based apps
- openvibe (in process)